Abstract
Neural Radiance Fields (NeRFs) have achieved impressive results in novel view synthesis but are less suited for large-scale scene reconstruction due to their reliance on dense per-ray sampling, which limits scalability and efficiency. In contrast, 3D Gaussian Splatting (3DGS) offers a more efficient alternative to computationally intensive volume rendering, enabling faster training and real-time rendering. Although recent efforts have extended 3DGS to large-scale settings, these methods often struggle to balance global structural coherence with local detail fidelity. Crucially, they also suffer from Gaussian redundancy due to a lack of effective geometric constraints, which further leads to rendering artifacts. To address these challenges, we present SplatCo, a structure–view collaborative Gaussian splatting framework for high-fidelity rendering of complex outdoor scenes. SplatCo builds upon three novel components: (1) a Cross-Structure Collaboration Module (CSCM) that combines global tri-plane representations, which capture coarse scene layouts, with local context grid features that represent fine details. This fusion is achieved through the proposed hierarchical compensation mechanism, ensuring both global spatial awareness and local detail preservation; (2) a Cross-View Pruning Mechanism (CVPM) that prunes overfitted or inaccurate Gaussians based on structural consistency, thereby improving storage efficiency while avoiding Gaussian rendering artifacts; (3) a Structure–View Co-learning (SVC) Module that aggregates structural gradients with view gradients, redirecting the Gaussian geometric and appearance attribute optimization more robustly guided by additional structural gradient flow. By combining these key components, SplatCo effectively achieves high-fidelity rendering for large-scale scenes. Comprehensive evaluations on 13 diverse large-scale scenes, including Mill19, MatrixCity, Tanks & Temples, WHU, and custom aerial captures, demonstrate that SplatCo establishes a new benchmark for high-fidelity rendering of large-scale unbounded scenes.
Method
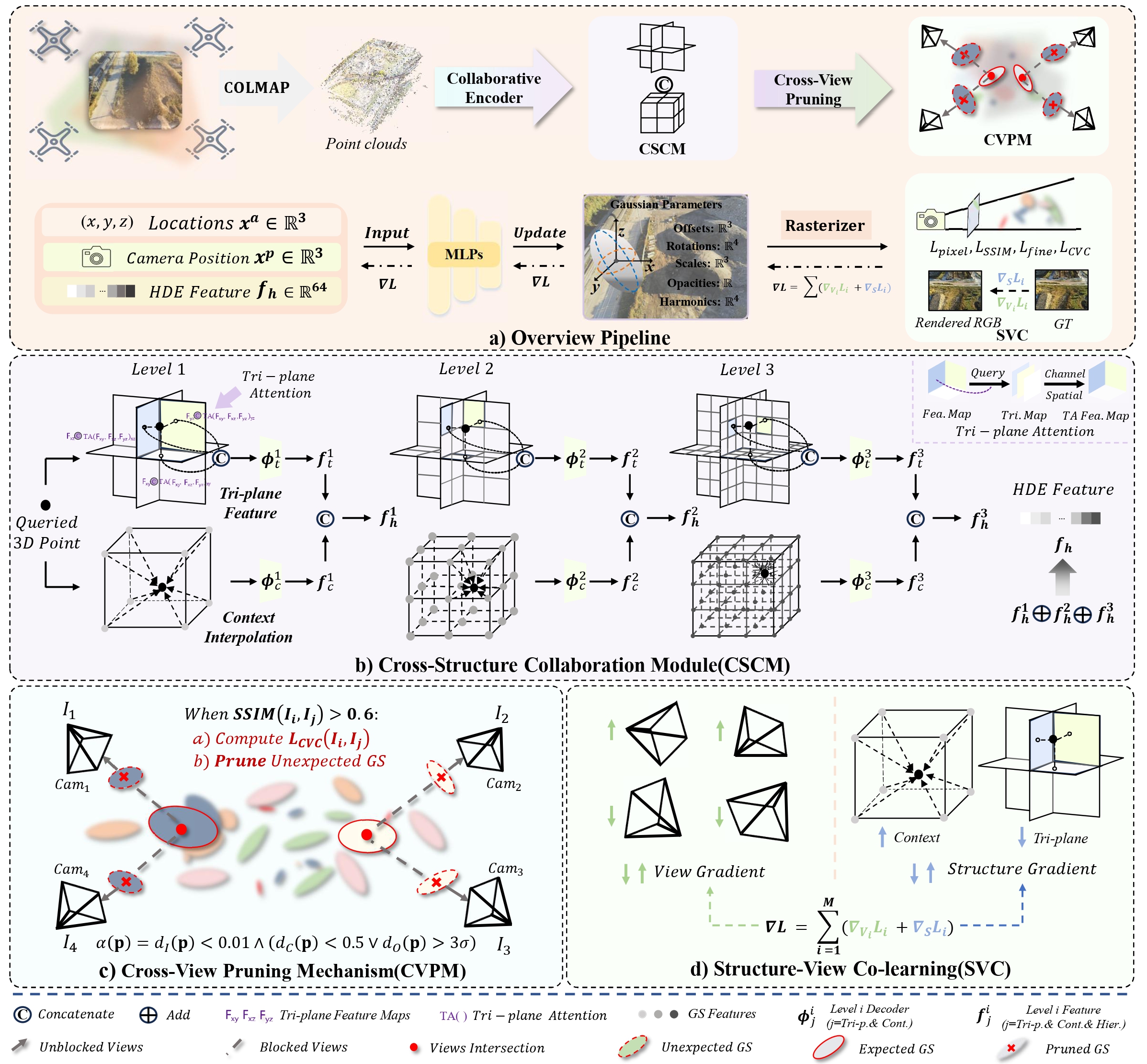
Overview of SplatCo. we first introduce the CSCM, which integrates multi-scale tri-planes and context-aware grids to generate Hierarchical Dense Embedded features \(f_h\), simultaneously ensuring global coherence and local detail preservation. Subsequently, the CVPM maintains integrity by employing a Cross-View Consistency Loss \(L_{CVC}\) and a geometric consistency-based pruning mechanism to reduce redundancy. Finally, the SVC module combines structural and view-dependent gradients for robust joint optimization.
Results

Qualitative comparison of our method with existing advanced techniques on the MatrixCity and Mill-19 datasets. Red boxes are used to highlight visual differences. As illustrated, in the building scene, our method achieves high-fidelity fine-grained reconstruction of complex textures, such as the exterior of solar panels, surpassing other methods. Please zoom in for more detailed visual results.

Visualization results on our custom SCUT_CA dataset. Highlighted regions (e.g. red boxes) reveal that our method renders significantly finer details and more realistic textures for elements such as leaves, lane markings, and distant objects, underscoring its superiority over competing approaches.

Results on the WHU dataset and plateau region scenes. Our method achieves highly realistic modeling of broad scene structures and precise capture of fine surface details. For instance, 'area1' showcases more authentic land and road structures. Simultaneously, our method accurately delineates subtle features like the distribution of vegetation on plateaus and the complex surface textures of sandy terrains, demonstrating superior structural awareness and detail retrieval.